Building a Local AI Home Setup: Home Assistant, Frigate and a Themed Dashboard
A local AI home setup means your house runs its automations, camera detection and voice control on hardware you own, with nothing piped out to a cloud service. It is equal parts practical and a good excuse to tinker. Here is how ours fits together, and what it takes to build your own.
To be clear on what we do: Scott’s Shipping Services does not sell the software. We import the hardware behind it, cleared and delivered, so the estimate below is for that import.
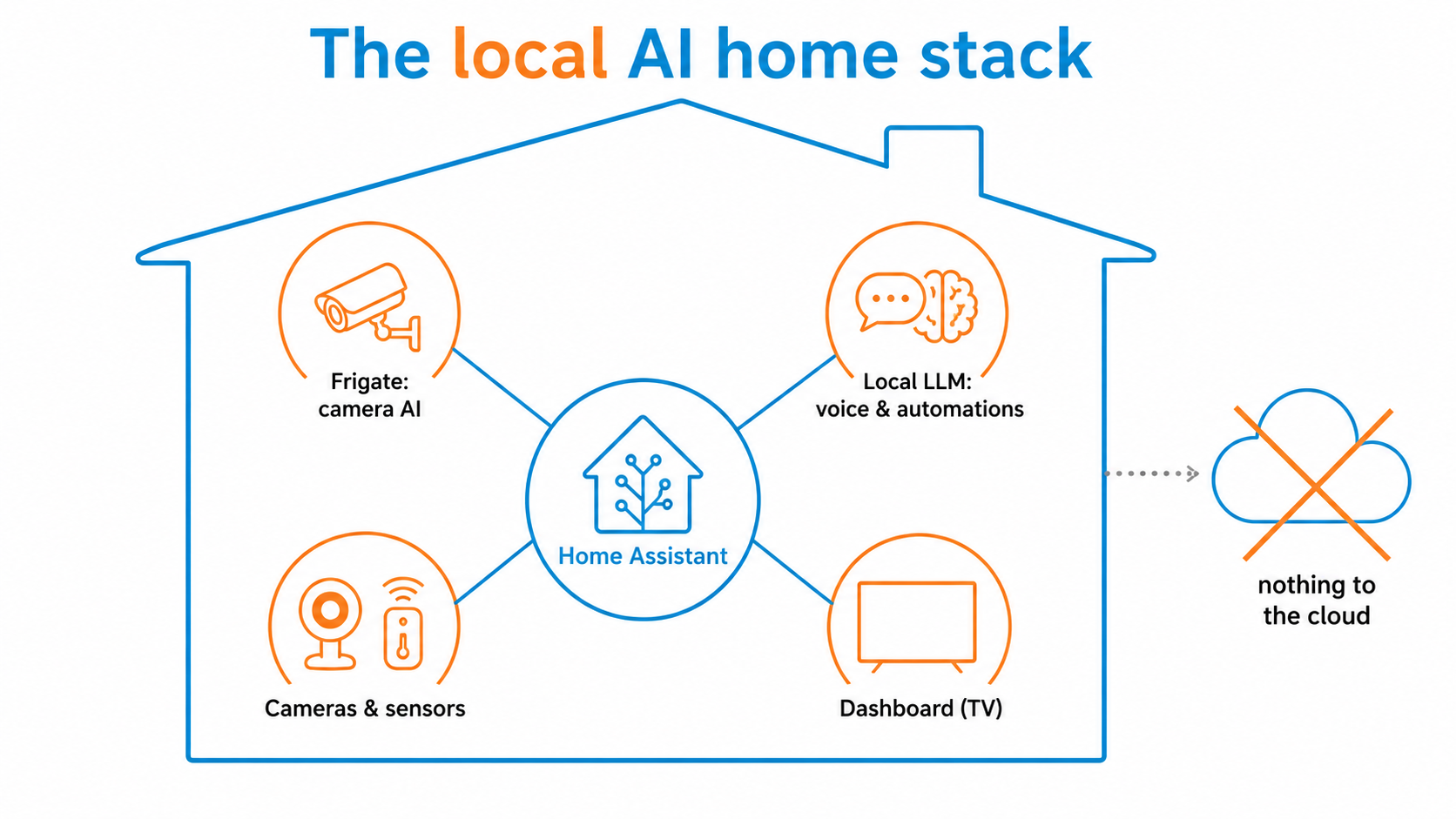
The hub is usually Home Assistant, the open-source platform that ties your lights, locks, sensors, cameras and energy gear together. The AI part is what you add on top: local camera detection, a model for voice and automations, and a dashboard to pull it all into one place. The common thread is that it runs on your own hardware, so the house keeps working even when the internet does not.
Camera detection without the cloud
Frigate is an open-source video recorder that does AI object and person detection locally on your camera feeds. It tells the difference between a person, a car and a cat without sending a frame of footage to anyone. Ours runs alongside Unifi cameras feeding into Home Assistant.
The win is plain: no monthly cloud-camera subscription, and no footage of your home sitting on someone else’s server. The detection happens in the house and stays there.
A model that helps run the house
A local LLM wired into Home Assistant gives you natural-language voice control and smarter automations without handing your home data to a third party. Ask it to set a scene, summarise what the cameras saw, or run a routine, and the request never leaves your network.
It pairs with the basics that make a home feel automated: presence detection that knows who is home, routines that run on their own, and energy gear reporting in real time.
Make it yours
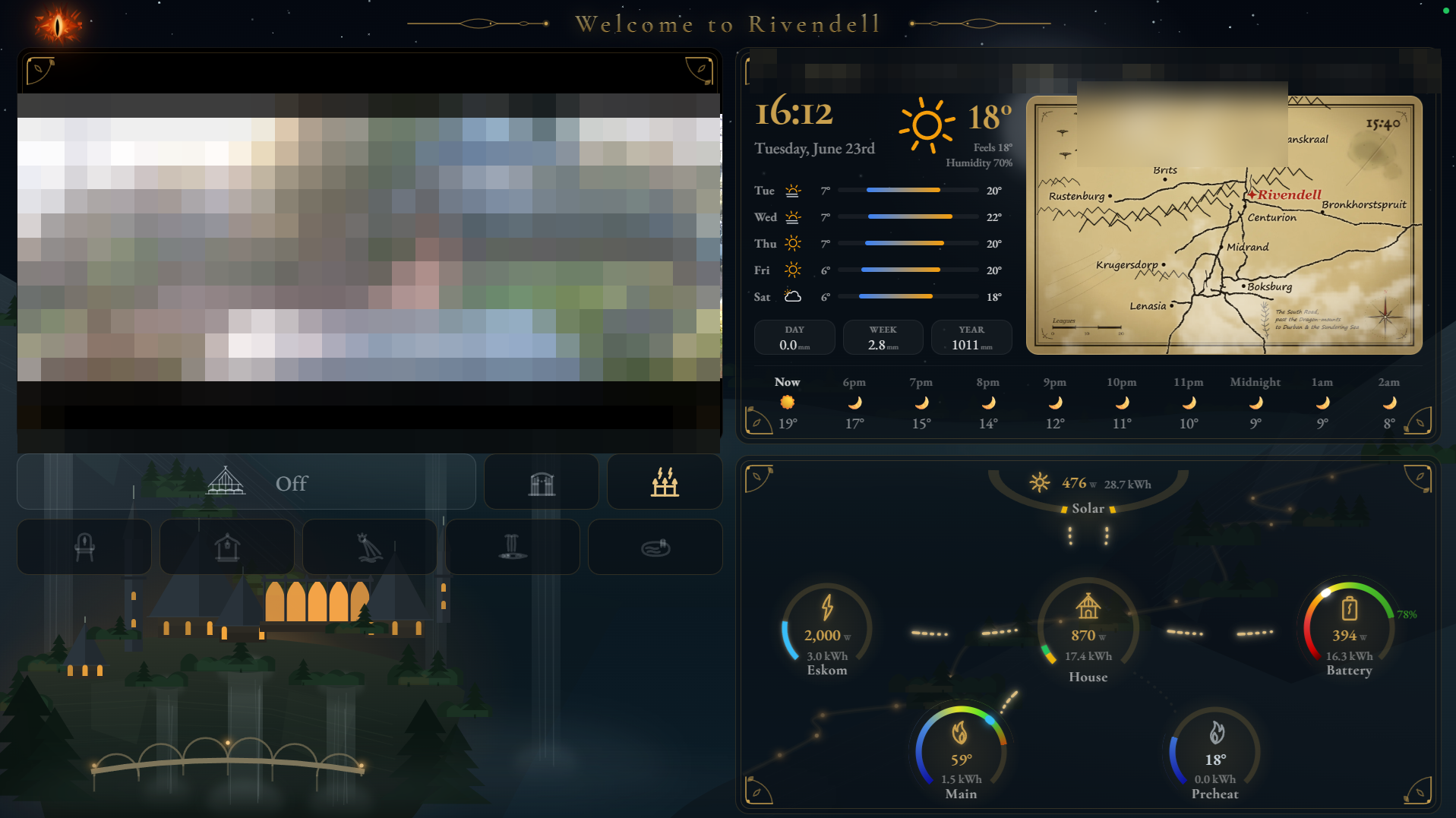
This is the part that turns a utility into a hobby. Ours is a themed dashboard for the TV called Rivendell, leaning shamelessly into Lord of the Rings, with tiles for weather, solar and battery, presence and the cameras, and an Eye of Sauron that scans the screen for no practical reason at all.
The point is that it is yours. Once the hardware is in the house, you are free to build something genuinely useful, faintly ridiculous, or both, with no subscription ticking over for the privilege.
What you need
You can start small. Frigate runs happily on modest hardware with a small AI accelerator, while a useful local LLM wants more memory behind it. The deciding spec, as always, is how much VRAM or unified memory you can put in front of the model.
It depends what you run. Frigate manages object detection on modest hardware with a small AI accelerator. A useful local LLM for voice and automations wants more memory behind it, which is where a capable GPU or a unified-memory box earns its place.
Is Frigate free?
Frigate is open source, so the software is free. You run it on your own hardware, which is where the cost and the privacy both sit with you rather than a subscription.
Can I run all this on a Raspberry Pi?
A Pi with an AI accelerator can handle light camera detection. A genuinely useful local language model needs more memory than a Pi offers, so most setups pair the Pi-class device for sensors with a stronger machine for the model.
Written by Scott Kirby, founder and director of Scott’s Shipping Services.
With years of hands-on experience in international shipping and South African customs, Scott started SSS to give individuals and businesses a simpler, more transparent way to import. He and his team have handled thousands of shipments from six continents, building a reputation for reliability, compliance, and honest pricing.
Using a Local LLM to Automate Your Small Business in South Africa
Most small businesses lose hours every week to repetitive admin: classifying items, chasing tracking numbers, sorting email, posting to social, pulling the same report again. A local LLM, running on a machine you own, can take the routine end of that off your plate without a monthly per-seat bill. Here is what automating a small South African operation actually looks like, using our own setup as the example.
To be clear on what we do: Scott’s Shipping Services does not sell the software. We import the hardware that runs it, cleared and delivered, so the estimate below is for landing that kit in South Africa.
The best candidates for automation are the same everywhere: repetitive, high-volume, low-judgement tasks that follow a pattern. The jobs nobody enjoys and everybody forgets. A local model is well suited to that end of the work, while anything needing real judgement stays with a person.
The point is not to replace your team. It is to stop them spending an afternoon on what a machine in the corner can do in the background.
Real examples from our own business
Scott’s Shipping Services runs on this kind of automation. A few of the jobs working in the background:
Customs-code classification. New orders are scanned and assigned the right tariff code, with dutiable items flagged for attention.
Invoice and order handling. Invoices matched to orders, depot arrivals tagged, and tracking numbers pulled out of a stream of carrier emails.
Email triage. Incoming mail sorted and categorised so the things that need a person surface first.
Scheduled reporting. The numbers that matter pulled together on a fixed schedule instead of by hand.
Content and social. A week of social posts drafted and scheduled at a time, plus the technical SEO and schema groundwork behind the website.
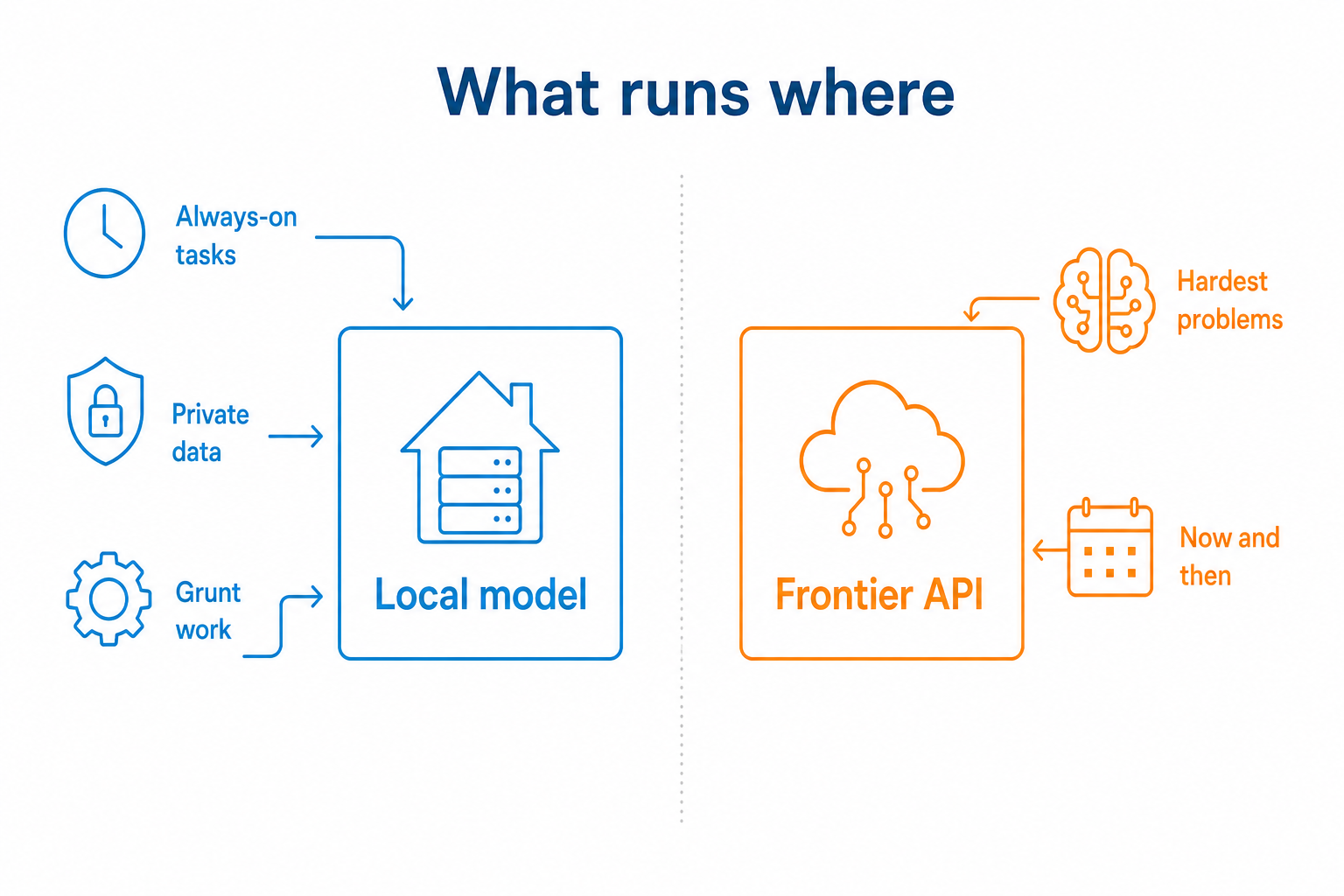
The always-on, repetitive end of all of it runs on a local model, with frontier APIs kept for the occasional hard problem.
Why run it locally
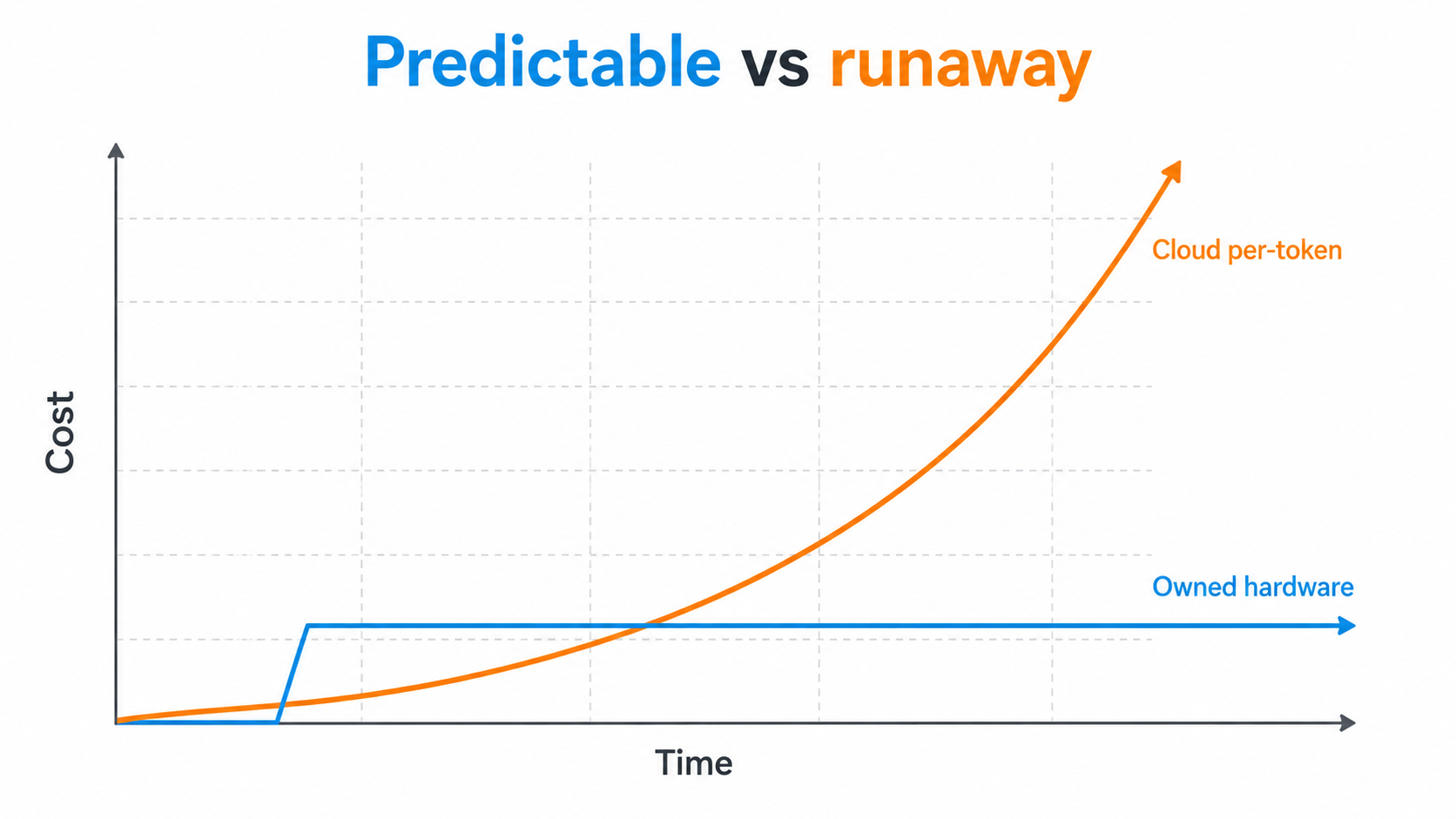
Predictable cost. No per-token meter, and no risk of a misconfigured job running up a large bill overnight. Once the hardware is paid for, the running cost is electricity.
Always on. A machine in the corner works day and night without a usage tab climbing in the background.
Your data stays yours. Customer details, invoices and order history stay on your own hardware rather than going to an outside provider.
Build out as you grow. Start with what you can fund, add capacity when the business calls for it. No tier you have to commit to up front.
What you actually need
You do not need a data centre. A capable workstation or a compact turnkey box is enough to start, and someone reasonably comfortable with tech to set it up. The deciding spec is memory, because that sets the size of model you can run.
It helps to have someone comfortable with tech. A clued-up IT person can stand up a capable machine and the open tools that run models on it. You do not need a full software team.
What can a local model realistically automate?
Repetitive, high-volume, pattern-based work: sorting, classifying, matching, drafting, summarising, scheduled reporting. Keep the judgement calls and anything high-stakes with a person.
Is it expensive?
It is an upfront hardware cost rather than a subscription, which makes it predictable. There is no per-seat or per-token bill climbing each month, and no surprise hikes.
Thinking about automating the admin? Use our online calculator for a quick estimate, or get in touch to source the hardware.
About the Author
Written by Scott Kirby, founder and director of Scott’s Shipping Services.
With years of hands-on experience in international shipping and South African customs, Scott started SSS to give individuals and businesses a simpler, more transparent way to import. He and his team have handled thousands of shipments from six continents, building a reputation for reliability, compliance, and honest pricing.
Local LLMs for Professional Firms in South Africa: POPIA, Data Control and Audit
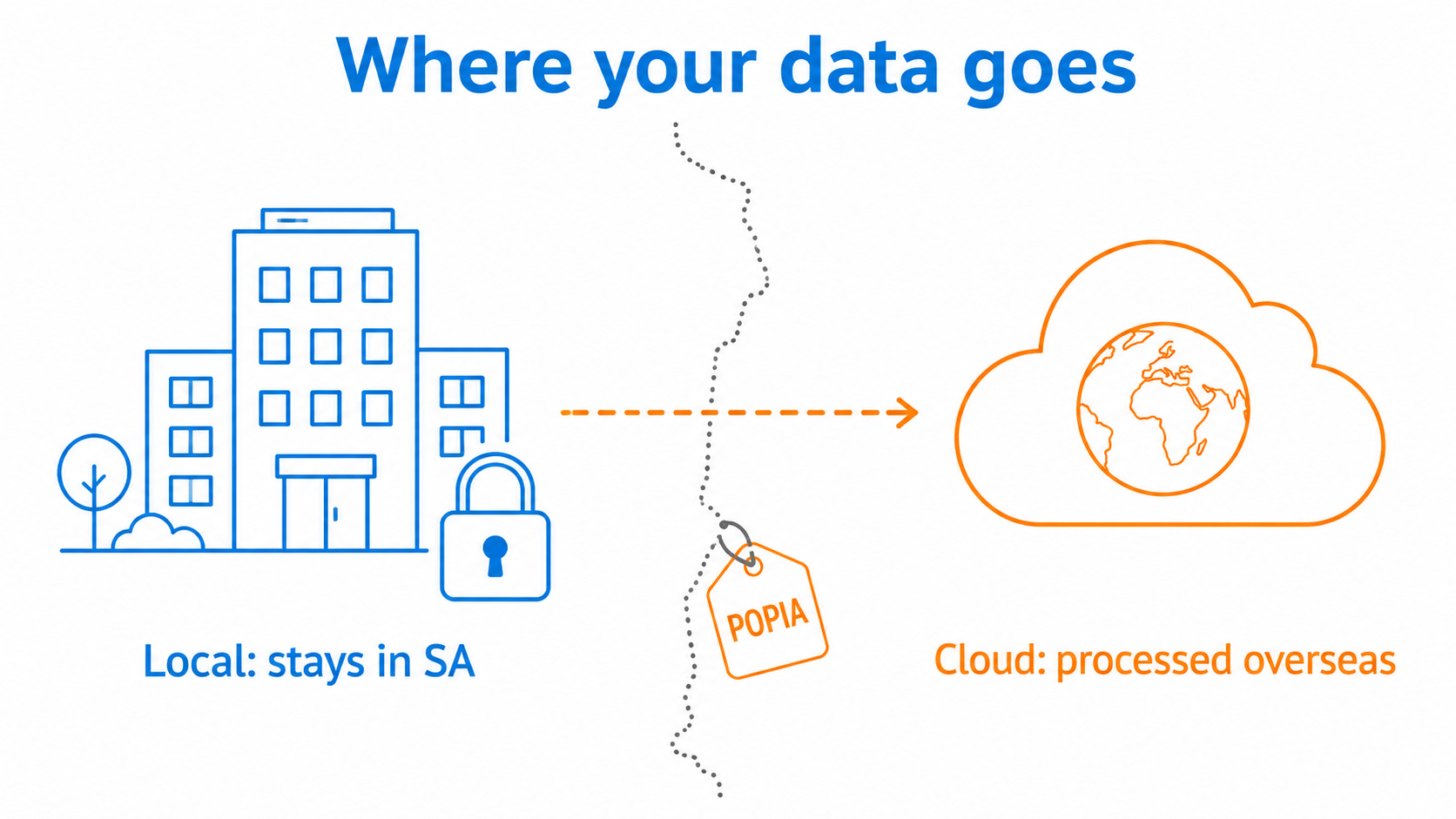
For a South African firm handling client money, medical records or legal files, the question with AI is not which model is cleverest. It is where your data goes. A local LLM, one that runs on hardware you own, keeps that data in the building, which is the cleanest answer to POPIA. This guide is for financial, medical and legal practices weighing AI against their compliance obligations.
To be clear on what we do: Scott’s Shipping Services does not sell the software. We import the hardware a local setup runs on, cleared and delivered, so the estimate below is for that import.
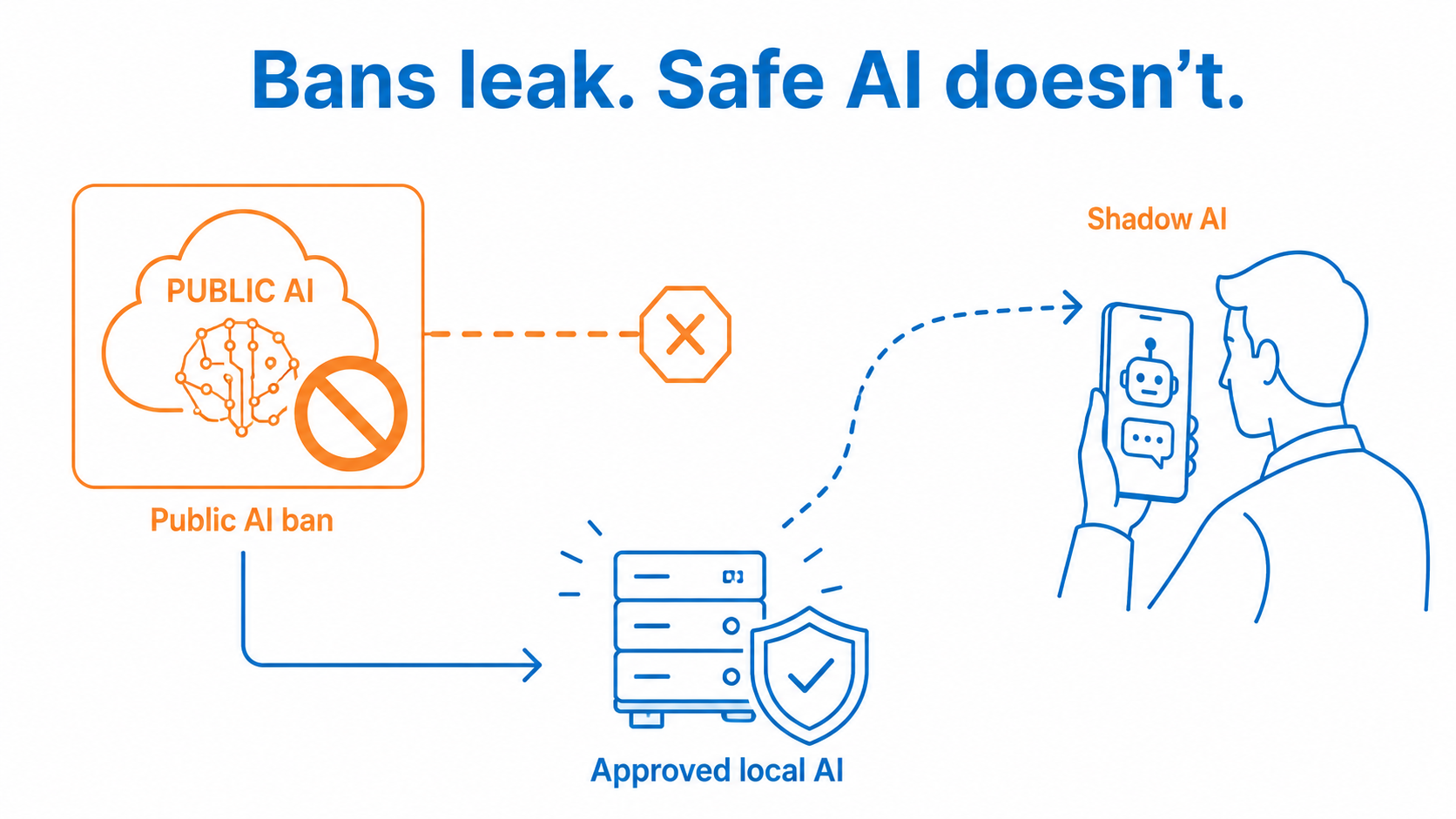
If your staff have deadlines and a phone, some of them are already pasting work into a public AI tool. Often that work contains client information. The common response is to block the public tools on the office network.
Blocks rarely hold. People switch to a personal phone or a home laptop, and the data leaves anyway, now with no oversight at all. A ban tends to push the problem underground rather than solve it. Giving staff a safe, sanctioned AI they are allowed to use is more effective than an unenforceable rule. A local model is that safe option, because the data stays inside your control.
Why cloud privacy promises may fall short of POPIA
POPIA governs how personal information is processed, including when it is sent across borders. The major AI providers are built around large-scale processing, much of it on overseas infrastructure. A professional or API plan still routes your prompts, and whatever you paste into them, to a processor outside South Africa.
A provider can offer a genuine privacy policy and still not line up neatly with what POPIA asks of you as the responsible party. The strongest data-residency and processing controls are usually reserved for large enterprise agreements, not the plans a typical firm signs up for. Running the model locally sidesteps the cross-border question entirely, because the data never leaves your premises.
This is general information, not legal advice. Where the line sits for your practice is a question for a compliance specialist, but the structural point holds: on-premises is the simplest position to defend.
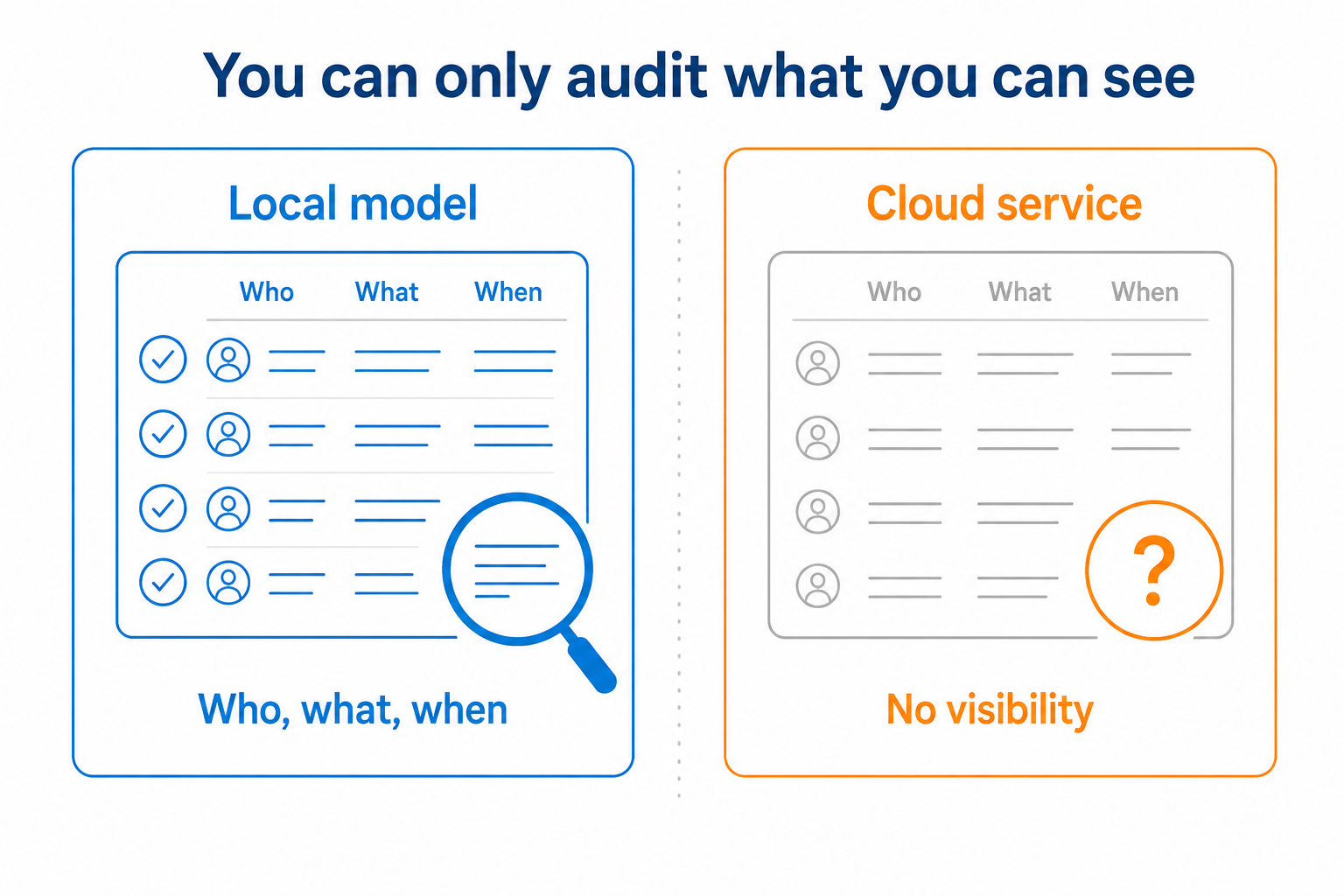
You can audit a local model
With a model on your own hardware, you own the logs. You can see what was asked, what came back, which user it came from, and when. If a result is later queried, or a process produces the wrong output, you can reconstruct exactly what happened.
With an external service you lose most of that visibility into per-user activity. For regulated work, where you may have to show who did what, a complete audit trail is not a nice-to-have. Owning the model means owning the record.
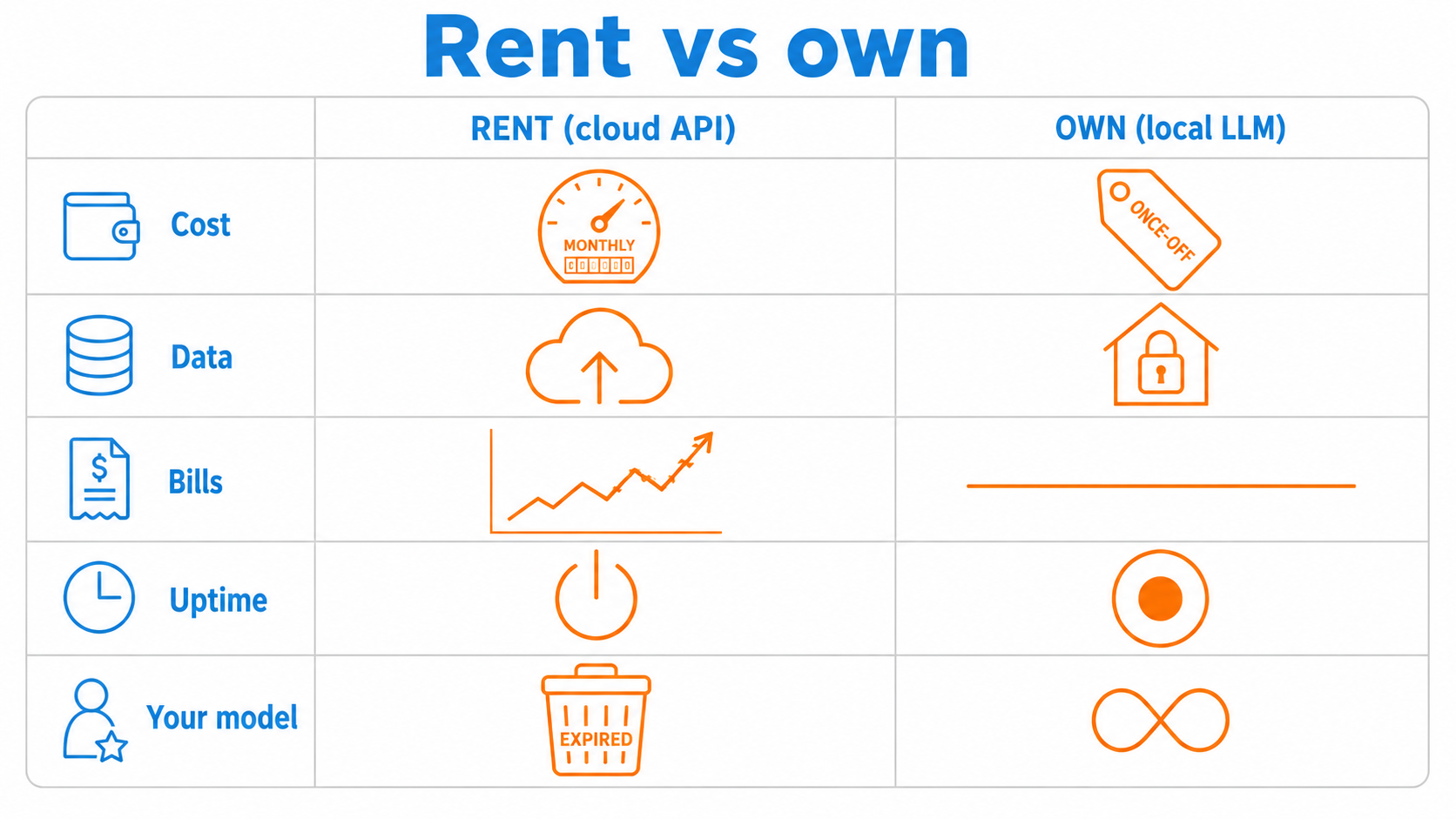
The runaway-cost risk
Cloud AI is billed by the token. One enthusiastic user, or a single misconfigured automation, can run up a large bill in a day. Keeping that in check means usage caps, monitoring and a layer of oversight you did not have before.
Owned hardware has a fixed cost. Once it is paid for, the meter does not run, and a novice cannot accidentally spend thousands overnight. For a small firm, predictable is worth a great deal.
What it looks like in practice
Most firms do not need to go all or nothing. The sensitive work, document review, drafting, extracting data from your own files, runs on a model in your office. Anything that is not confidential can still use a frontier API when you want the extra capability.
The hardware that makes this practical, from a compact machine like the NVIDIA DGX Spark or AMD Strix Halo to a GPU workstation, does not land easily in South Africa. Scott’s Shipping Services imports it, clears it, and delivers it as one all-inclusive quote. For the full breakdown of what to buy, see our guide to importing AI and local-LLM hardware into South Africa, and the wider case for owning your AI hardware. If you want us to source specific parts, that is our international shopping concierge.
Compliance depends on your whole setup, not one tool. What a local model does is remove the cross-border processing question that makes cloud AI hard to square with POPIA, because the data stays on your premises. Confirm the specifics for your practice with a compliance specialist.
Can I not just use the privacy settings on ChatGPT or similar?
Professional and API plans still process your data with a provider outside South Africa, and the strongest data-residency controls are generally enterprise-only. A local model keeps the data in-house, which is a simpler position to defend.
What hardware does a small firm need?
It depends on the size of model you want to run, and the deciding spec is memory. Our guide to importing AI and local-LLM hardware into South Africa breaks down the options, from a single workstation to a turnkey box.
Does SSS give legal or compliance advice?
No. We import the hardware, cleared and delivered. The legal and compliance side is for a specialist in that field. Tell us what you want to run and we will help you land the right kit.
Weighing a private AI setup for your firm? Use our online calculator for a quick estimate, or get in touch to source the hardware.
About the Author
Written by Scott Kirby, founder and director of Scott’s Shipping Services.
With years of hands-on experience in international shipping and South African customs, Scott started SSS to give individuals and businesses a simpler, more transparent way to import. He and his team have handled thousands of shipments from six continents, building a reputation for reliability, compliance, and honest pricing.
Why Run a Local LLM? The Case for Owning Your AI Hardware
Running a local LLM means hosting an AI model on hardware you own instead of renting access through a cloud API. For South African professionals, builders and businesses, owning the hardware is what turns AI from a monthly bill into an asset you control. This is the case for going local: what you gain, who it suits, and the kind of work it already does.
We do not sell the model. What we do is import the hardware it runs on, cleared and delivered to your door, so the estimate below is for landing that kit in South Africa.
It keeps working. A model on your own hardware does not care about sanctions, export bans, account suspensions or a provider pulling out of the South African market. Nobody can switch it off.
Your data stays put. Nothing is uploaded to a third party. For anyone handling client records, case files, patient data or financials, that is the difference between compliant and not under POPIA.
You pay for it once. No subscription, no per-token meter running in the background, no price hike landing on a Tuesday. The cost is the hardware you already own.
No runaway bills. A misconfigured script cannot quietly burn thousands in API tokens overnight. There is no meter to run away with.
You keep what works. A model that suits your workflow will not be deprecated or retired out from under you. Pin the version that works and run it for years.
Right tool, right cost. Run the repetitive, always-on grunt work on your own model, and save the frontier APIs for the genuinely hard problems. Most jobs do not need a flagship model.
Who it is for, and what it does
Professionals who need it now
Doctors, lawyers, accountants and developers working with confidential or regulated data cannot push it to a cloud API and hope for the best. Local is the compliant route, and usually the urgent one. The data control, POPIA and audit side of this runs deep, so we covered it on its own: local LLMs for professional firms in South Africa.
Builders and IT consultants
Developers who build AI tools and sell them to several companies need to own the stack they ship. We have built our own at SSS: a custom CRM shaped around how the business runs, and a WhatsApp bot for customer queries, the channel most South Africans actually use. On hardware you control, you build and test without a token meter running, and you are not handing your clients’ workflows to a third party you cannot vouch for.
Small businesses with a clued-up IT person
If you have someone who can put a capable machine in the corner, you can automate the work that quietly eats hours: customs-code classification, email triage, scheduled reporting, social posting. A local model runs the always-on, repetitive end of it while the frontier APIs handle the rest. We walk through the real examples in using a local LLM to automate your small business.
Hobbyists and tinkerers
Plenty of this starts as a hobby and turns into something real: home automation, local camera detection, a themed dashboard on the TV. Running the AI side on your own hardware means no subscription for something you built for yourself, and full freedom to tinker. Ours leans Lord of the Rings, and we show how it fits together in building a local AI home setup.
Where SSS comes in
Every one of these benefits depends on one thing: owning the hardware. That is the part that does not land easily in South Africa.
Scott’s Shipping Services sources the GPUs, mini-supercomputers and high-VRAM cards local models run on, handles the customs classification, duties and VAT, and delivers it landed as one all-inclusive quote. For the full breakdown of what to buy, see our guide to importing AI and local-LLM hardware into South Africa. If you want us to buy specific parts on your behalf, that is our international shopping concierge.
For plenty of work, a cloud API is fine. Local wins when privacy matters, when you want predictable costs instead of a per-token meter, or when the job needs to run all day every day. Many setups do both: local for the routine work, cloud for the hardest problems.
Is a local model as good as ChatGPT or Claude?
The frontier cloud models still lead on the hardest tasks. For everyday work, coding help, summarising, drafting and the repetitive grunt work, open models you can run locally are now strong enough that most users would not notice the difference.
We are the import side: we get the right hardware into South Africa, cleared and delivered. We are not a managed AI service, but tell us what you want to run and we will help you land the parts that fit.
Written by Scott Kirby, founder and director of Scott’s Shipping Services.
With years of hands-on experience in international shipping and South African customs, Scott started SSS to give individuals and businesses a simpler, more transparent way to import. He and his team have handled thousands of shipments from six continents, building a reputation for reliability, compliance, and honest pricing.
Importing AI and Local-LLM Hardware into South Africa
Importing AI hardware into South Africa means getting the GPUs, mini-supercomputers and high-VRAM cards that local LLMs run on past two obstacles: thin local supply and a customs process that treats high-value electronics with suspicion. This guide covers what people are actually running local models on in 2026, the grey-market parts worth knowing about, and how Scott’s Shipping Services brings it in as one all-inclusive price.
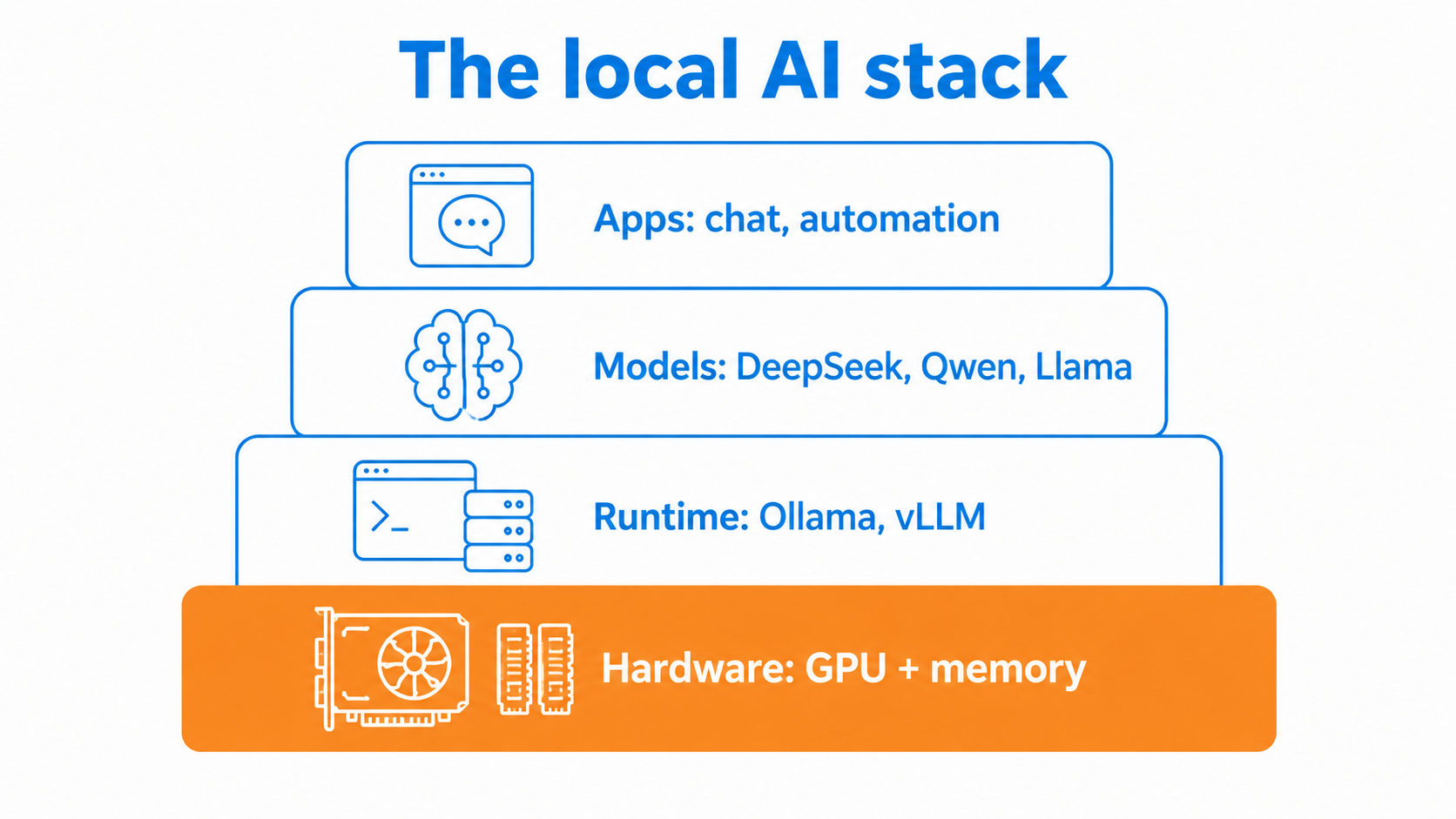
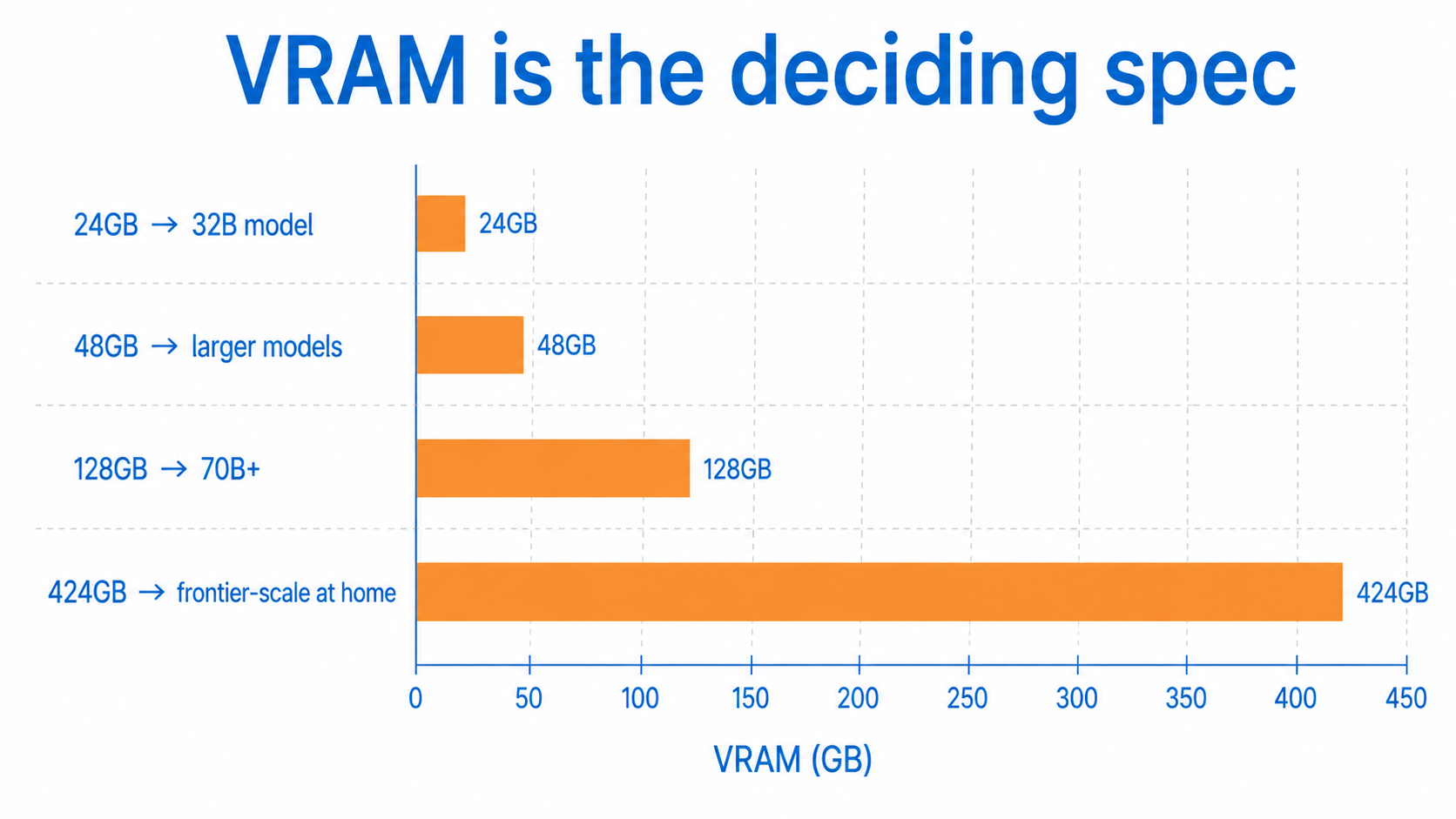
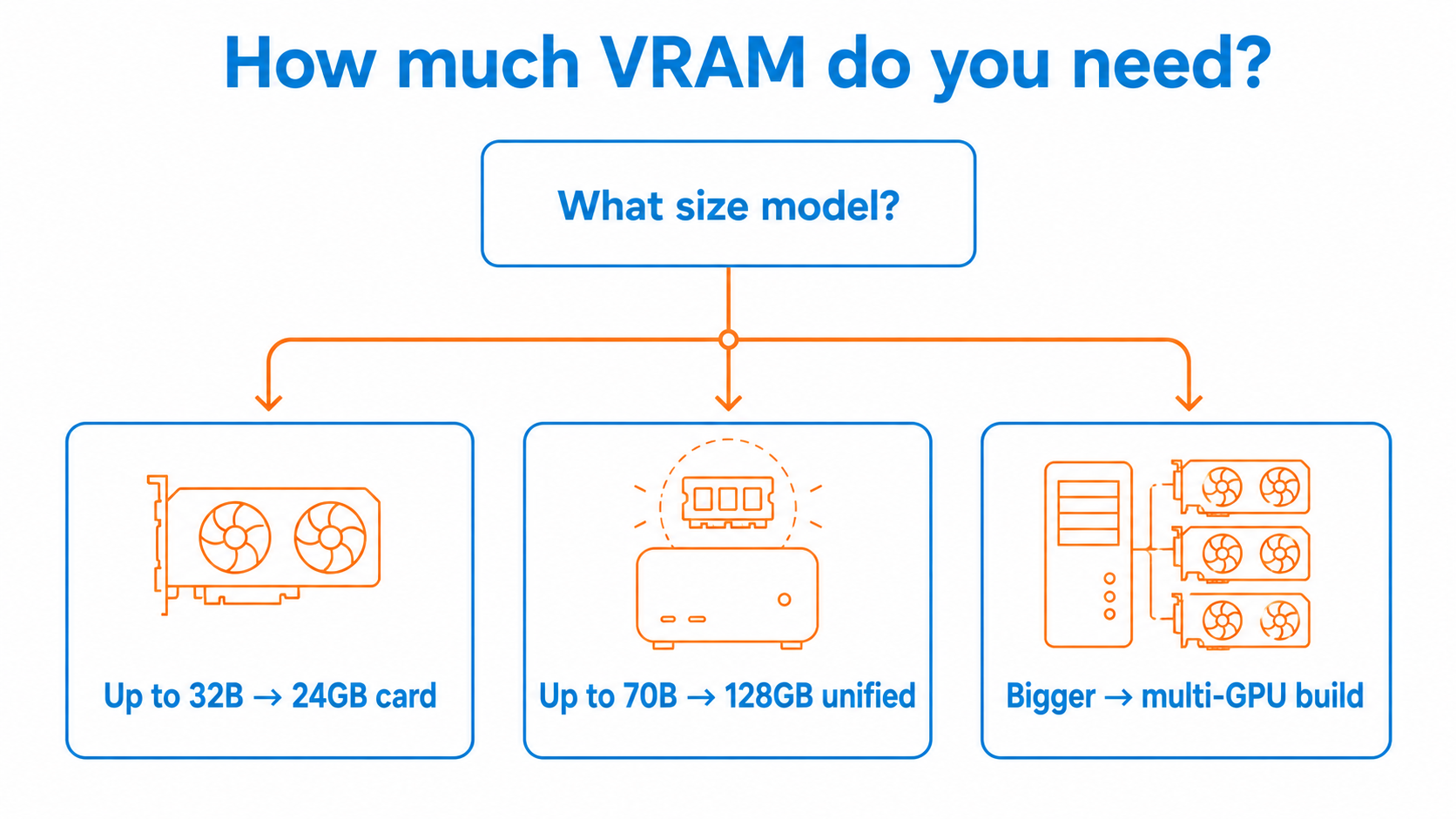
Local LLM hardware is the compute you need to run open-weight models like DeepSeek, Qwen and Llama on your own machine instead of a cloud API. The deciding spec is memory: how much VRAM or unified memory you can put in front of the model.
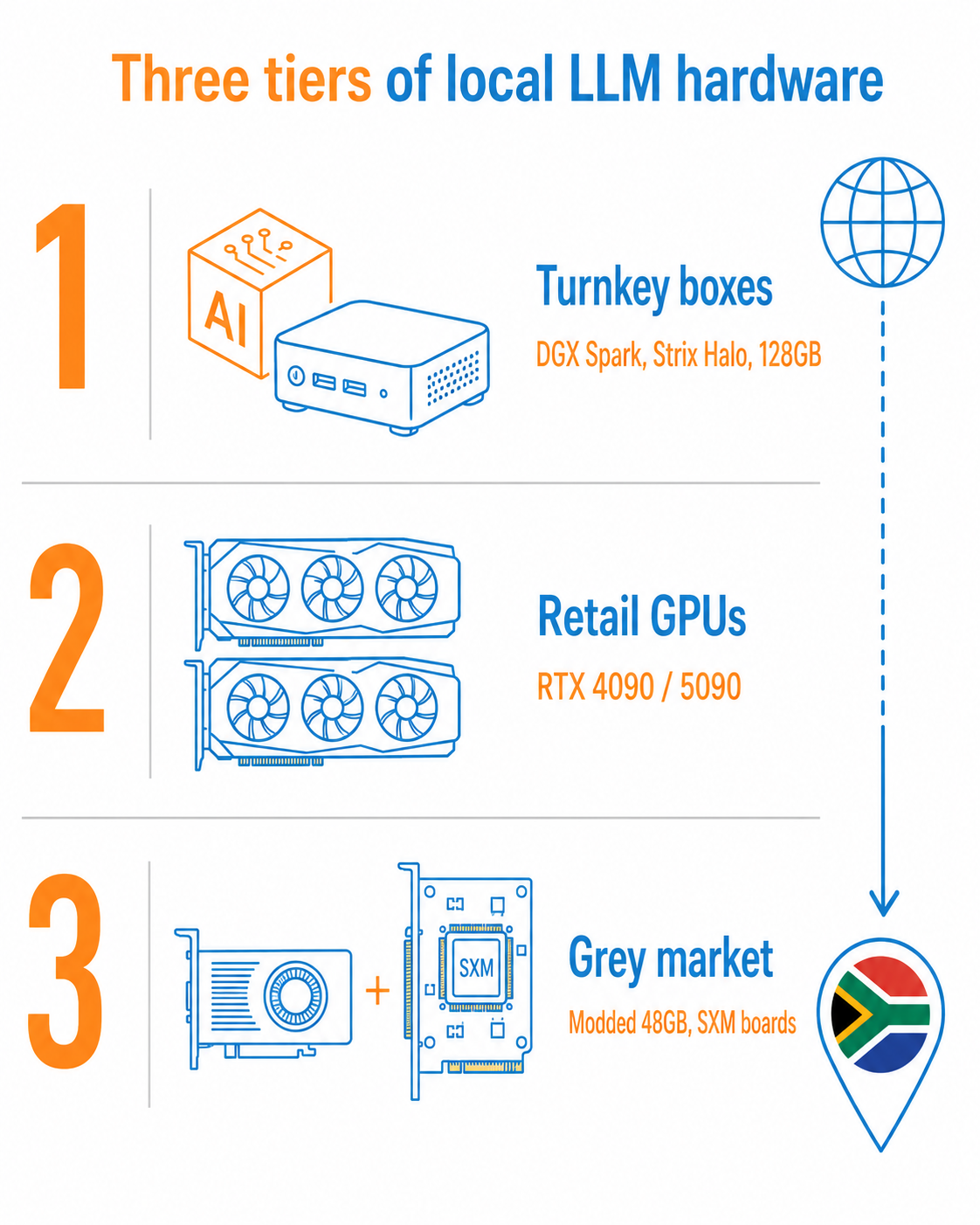
The hardware splits into three tiers. Turnkey boxes like the NVIDIA DGX Spark and AMD Strix Halo mini PCs ship with 128GB of unified memory. Retail GPUs like the RTX 4090 and 5090 remain the single-card workhorses. Grey-market gear covers China-modded 48GB RTX 4090s and ex-datacentre cards mounted on adapter boards.
Almost none of it sits on a South African shelf, and the modded parts carry real risk. SSS sources the hardware, handles the customs classification, duties and VAT, and delivers it landed as one quote.
What is driving the demand
Two things turned self-hosting from a niche hobby into a queue of buyers. The first is the open Chinese models. DeepSeek and Qwen now ship open-weight releases that hold their own against commercial APIs, and at 4-bit quantisation a capable model like DeepSeek-R1 32B fits on a single 24GB card. Good models that run on hardware you can own are the whole driver.
The second is Odysseus, the self-hosted AI workspace released by Felix Kjellberg (PewDiePie) on 31 May 2026. It runs local backends like Ollama, vLLM and llama.cpp, and his own rig of eight modded RTX 4090s plus two RTX 4000 Ada cards put a real number on what a serious local setup looks like. The result is a wave of people pricing their own builds.
What people actually run local LLMs on
Turnkey boxes: DGX Spark and Strix Halo
The NVIDIA DGX Spark is built around the Grace Blackwell GB10 chip with 128GB of unified memory, enough to load models up to roughly 200 billion parameters in NVFP4. It runs them at around 35 to 80 tokens per second, with memory bandwidth near 273 GB/s as the main limit. Even abroad it has been supply-constrained, with multi-week lead times.
The AMD Strix Halo (Ryzen AI Max+ 395) pairs 16 Zen 5 cores with an integrated Radeon 8060S and up to 128GB of shared memory, leaving roughly 115 to 120GB usable for inference. It loads a 70B model without splitting it across cards and pushes a 30B model at around 100 tokens per second. It has become the practical all-rounder for a quiet desktop or air-gapped build.
Retail GPUs: RTX 4090 and 5090
The RTX 4090 with 24GB remains the best single-card option, handling 32B models at Q4 with room for cache. The RTX 5090 at 32GB lifts that ceiling, and two cards together open up larger models. The constraint in South Africa is not whether they work, it is getting current stock at a sane price.
The grey market: modded cards and adapter boards
This is where the buzz gets loud and the risk gets real.
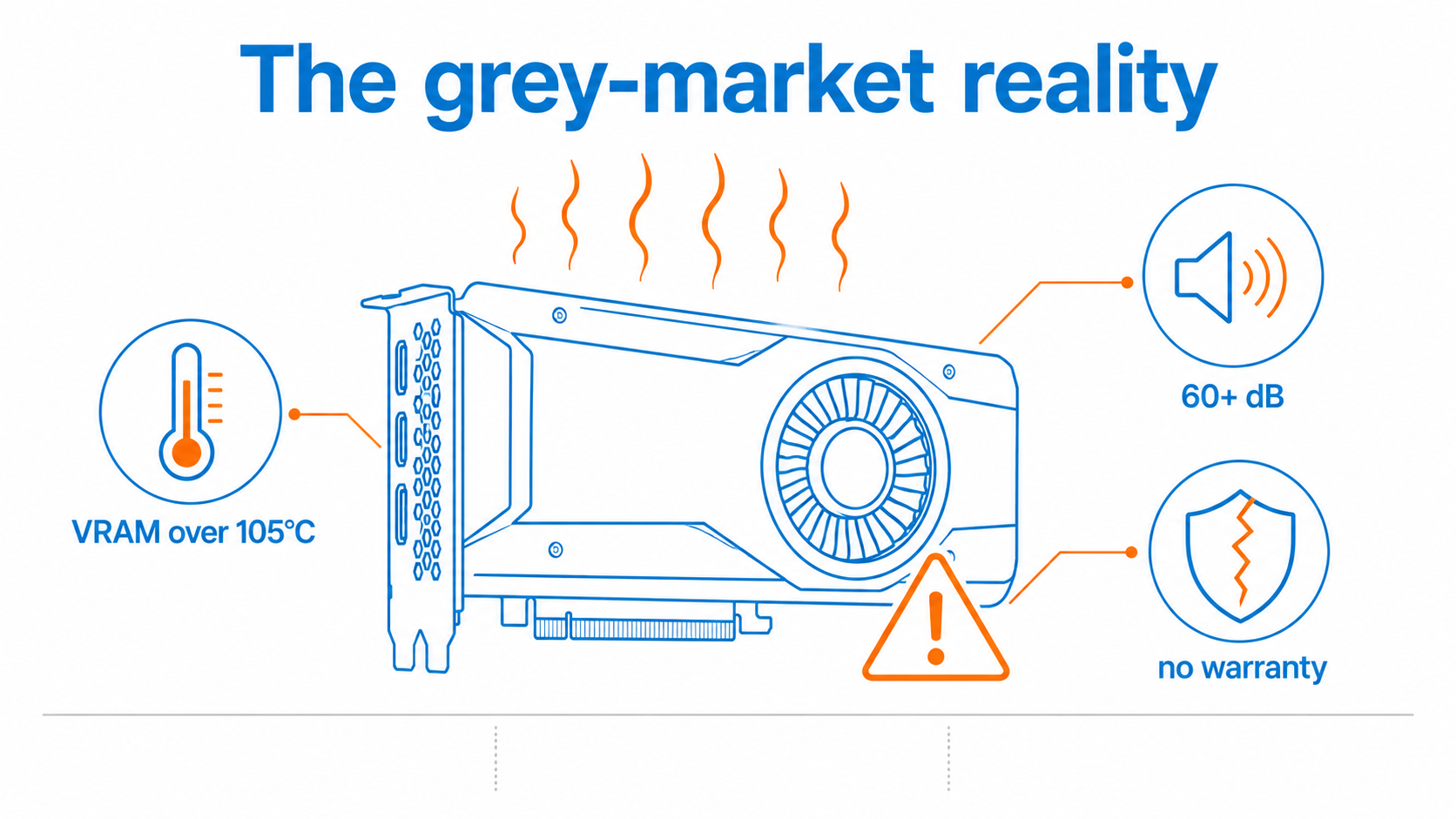
Modded 48GB RTX 4090s. NVIDIA never made a 48GB 4090. These are custom builds out of China that reball the memory to double the VRAM, sold mostly on Alibaba and AliExpress as blower-style cards. On paper a 48GB card for large-model work is tempting. In practice, independent reviewers have measured VRAM temperatures above 105°C, blower noise past 60 dB, and stress-test failure rates several times higher than stock cards, often built on second-hand chips with no warranty.
SXM2 and SXM4 adapter boards. These breakout boards drop ex-datacentre modules like the Tesla V100, P100 and A100 into a normal PCIe slot. The VRAM-per-rand maths looks great, but power delivery, cooling and BIOS quirks make these a project build, not a plug-and-play card.
The grey market is exactly where buying blind costs money. A card that arrives dead, or cooks itself in a fortnight, has no recourse when you ordered it solo off a marketplace listing. This is the part of the market where knowing which sellers and which parts are worth touching is the whole value.
Memory and storage worth importing too
Compute is only half a build. Running a model larger than your VRAM means offloading layers to system memory, so DDR5 capacity and speed matter for anyone pushing past their card. Model weights also have to live somewhere fast: a 70B model at Q4 is around 40GB, and the largest open models run into hundreds of gigabytes, so a quick NVMe SSD earns its place.
It is usually worth importing the RAM and storage on the same shipment as the compute. One consignment, one customs entry, one delivery.
Why this hardware is hard to get in South Africa
Local stock is thin past a retail 4090. Turnkey AI boxes and datacentre-class cards rarely reach South African shelves at all, and when they do the markup reflects the scarcity.
High-value electronics also draw SARS attention. Correct tariff classification, an honest customs value, duties where they apply and VAT at 15% are all part of the entry. Get the paperwork wrong and a costly parcel sits in limbo while it is queried. For how that valuation is worked out, see our guide on how customs value is determined in South Africa.
Buying grey-market parts yourself stacks a second risk on top: if the card is faulty on arrival, you are arguing with an overseas marketplace seller, not a local supplier.
How SSS gets it in for you
Scott’s Shipping Services is an end-to-end import service. We buy the hardware, ship it, clear it through customs, pay the duties and VAT, and deliver it to your door as one all-inclusive quote. We do not do clearing-only work or handle goods you have already bought.
Sourcing judgement. We work with reputable suppliers, and where a build calls for grey-market parts we know which sellers and which cards are worth the risk and which to avoid.
Clean customs entries. High-value electronics get the correct HS classification and an honest customs value before they ship, so clearance stays fast and defensible if SARS asks questions.
Can you import a DGX Spark or Strix Halo machine to South Africa?
Yes. We source turnkey AI machines like the NVIDIA DGX Spark and AMD Strix Halo mini PCs from overseas suppliers and handle the full import, including customs, VAT and delivery. Lead times depend on stock abroad, which has been tight, so it is worth asking early.
Are the China-modded 48GB RTX 4090 cards worth it?
Sometimes, with eyes open. They offer a lot of VRAM, but they are custom builds with reported thermal and reliability problems and no warranty. If a build genuinely needs that much VRAM, we can advise on whether a modded card or a different route makes more sense, and source accordingly.
Can you get ex-server GPUs like the V100 or A100 and the adapter boards?
Yes. We can source datacentre cards and the SXM-to-PCIe adapter boards they need. These are involved builds, so we will be straight with you about the power and cooling they demand before you commit.
Do I pay duty and VAT on AI hardware?
VAT at 15% applies to imported hardware. Whether duty applies, and at what rate, depends on the exact tariff classification of the item. We confirm the classification and the full landed cost before you commit, so there are no surprises at clearance.
What does it cost to import a local LLM rig?
It depends on the parts, the source country and the shipment weight. We quote the whole job as one figure, with the hardware, shipping, customs, duties, VAT and delivery included. Get a quick estimate to see your landed cost.
Can SSS advise on what hardware to buy?
We are importers, not a build shop, but we know the market well. Tell us the models you want to run or the rig you are copying, and we will help you land the right parts reliably.
Planning an AI or local-LLM build? Use our online calculator for a quick estimate, or get in touch to source the parts.
About the Author
Written by Scott Kirby, founder and director of Scott’s Shipping Services.
With years of hands-on experience in international shipping and South African customs, Scott started SSS to give individuals and businesses a simpler, more transparent way to import. He and his team have handled thousands of shipments from six continents, building a reputation for reliability, compliance, and honest pricing.
Sending your request…
We’ll review and respond via email as soon as possible.
Open: 8 am – 5 pm weekdays Closed: Weekends & public holidays